今日は,少し真面目な帯域計測方法について.
スループットが100Mbps出るとは?
スループットが100Mbps出るとは,(1個のデータパケットのサイズが1,500Byteの場合)1秒間にパケットを533,333個(100M / (1,500 * 8))受信できることを意味しますが,これを2つパケットの送受信間隔に目を向けると,最低でも120μ秒間隔*1でパケットを送受信することができる(1,500 * 8 / 100M)と捉えることができます*2.ここから,送受信間隔を観測することでスループット(≒自分が利用できる帯域)を推測できるのではないかと言う考えが生まれます.
ICMPパケットを利用して2パケットの受信間隔を観測するプログラム
あるホストへICMP ECHO REQUESTパケットを送信すると,そのホストはパケットを受信すると(多分)即座にICMP ECHO REPLYパケットを返します.この機能を利用して,送信時に適当な間隔でICMP ECHO REQUESTパケットを送信し,対応するICMP ECHO REPLYパケットの受信間隔がどうなるかを観測するプログラムを作成してみます.
ソースコードは,msocket_20081106.tar.gz (with clx_0.13.2.tar.gz)になります(ネットワーク帯域計測プログラムで作成したプログラムも含まれていますが,必要なのはcheck_interval.cppとicmp_msocket.hだけです).今回は,説明する事はこれまでに説明したプログラムとあまり差がないので,ソースコードの記載&説明は省きます.ライブラリの使い方などは,
辺りを参考にして下さい.
#!/bin/sh addr=$1 file=$2 trial=80 i=10 while test $i -le 40 do echo "./check_interval $addr -i $i -n $trial >> $file" ./check_interval $addr -i $i -n $trial >> $file let i=i+2 done
作成したプログラムを上記のシェルスクリプトで走らせてICMPパケットの送受信間隔を観測した結果が以下のグラフになります.図の点は40サンプルの平均値で,エラーバーは95%信頼区間です.
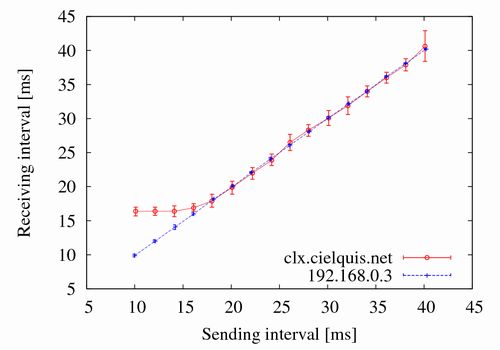
ホストは,LAN内のPC(192.168.0.3)とインターネット越しにあるレンタルサーバ(clx.cielquis.net)を選んでみました.192.168.0.3の場合は,送信間隔と受信間隔がずっと同じなのが分かります.これは,LAN内なら100Mbps近く出る(120μs間隔でパケットを送受信できる)ので,10msがそれと比較して十分余裕のある間隔だからです.一方,clx.cielquis.netの場合は17ms辺りが限界で,それより小さい間隔で送信したとしても受信間隔は17msに広がっています.パケット間隔が17msだと,約700kbps(1,500 * 8 / 0.017)と言うことになります.Radish Networkspeed testingを用いて計測してみたところ,上り710.6kbps,下り1.226Mbpsだったので,恐らく送信時の最初の1ホップがボトルネックになっているのだろうと予想されます.
図を見ても分かりますが,限界を超える(今回の例だと17ms以下)とほぼ限界近くの受信間隔が観測されるようになるので,できるだけ小さな間隔でICMP ECHO REQUESTパケットを送信して,対応するICMP ECHO REPLYパケットの受信間隔からスループットを推測する,と言う方法でもそれなりに有用な値を取得することができます.実験した限りだと,10パケット程度でも有用と思われる程度の観測結果が得られたので(観測される受信間隔のバラつきが小さかった),普段やるような計測方法(数百KB〜数MBのファイルをアップロード/ダウンロードしてスループットを計測する)よりもずっと少ないパケット数で計測を行うことができそうです.また,この結果と実際にデータ転送をしたときのスループットを比較することで,スループットが受信間隔から推測されるスループットに比べて著しく低い場合は,バッファが小さすぎてまったく通信できてない空白時間があるのでは,とか,あんまり大量のデータ転送をしてどっかで制限かけられたのでは:p,などと言ったスループットが出ない原因追求の補助として利用することもできます.
パケット間隔ベースの計測手法の基本はこんな感じで,後はいかに“賢く”送信間隔を決定するかとか,いかに計測パケット数を抑えるか,と言ったことを考えながら皆あれこれ提案しています.
注意事項
注意事項というか何と言うか.
まず,1つ目はパケット間隔ベースの計測プログラムを作るときには,パケット送信のスケジューリングや時刻取得にかなりの細かい粒度を求められる,と言うことです.作成したプログラムは,パケット送信のスケジューリングにはselect(),時刻取得にはQueryPerformanceCounter()(UNIX系の場合はgettimeofday())を利用して一応μ秒単位で操作できるようにしたのですが,テストしたところ1ms以下だと精度があやしいようです.パケット間隔1msは12Mbps相当なので,10Mbps以上スループットが出せるような環境だと信頼性がかなり落ちそうな予感がします.
2つ目は,実験結果からも分かりますが,ADSLのようにアップロード帯域とダウンロード帯域が違う場合,(多くはアップロード帯域が抑えられているので)アップロード帯域の値が計測結果として得られてしまいます.計測したいのはダウンロード時のスループット,と言うことが多いのでこれはネックとなりそうです.ICMPを使うんじゃなくて,httpによるダウンロード時にパケット間隔を観測する方法を組み込む方法が(パケットの送信間隔を弄るとかができないけど)現実解なのかな,とちょっと感じています.
最後は,ping floodに関すること.多くのサーバは,短い時間に大量のICMP ECHO REQUESTパケットが到着すると弾くように設定されています(そもそも,ICMPを受け付けていない場合もありますが).最初,10秒単位くらいで見て秒間1パケット送ってなかったら大丈夫だろう,と甘く考えてたのですが,バースト的に送ってしまうとその時点でアウトだったりするようです.現在のプログラムでは,2パケット送ったら4秒スリープする(0.5パケット/秒相当)ように設定しています.これはプログラムオプションでは変更できないようにしています.defineしているのでプログラム見ればすぐ変更できますが,あんまり大量のパケットをバースト的に送信して怒られても知りません:p
Download
- msocket_20081106.tar.gz
- msocket_20081106_win32.zip ..... Windows用のバイナリ付
- CLX C++ Libraries ..... 上記のプログラムをコンパイルする際に必要となるライブラリ
Usage
usage: check_interval hostname [options] options: -i # (msec) sending interval -l # (byte) data length -n # number of probing packets -t # (sec) timeout value -v print debug information
測定したいホスト名を最初に与えます.オプションは5つで,iオプションはICMP ECHO REQUESTの送信間隔をミリ秒単位で指定します.lオプションは,ICMPパケットのデータ長を指定します.nオプションは,計測に使用するパケット数を指定します.2パケットで1個の結果を得るようになっているので,得られる結果はn/2個となります.tオプションは,ICMP ECHO REQUSTを送信してから最大で何秒待つか指定します.ここで指定された時間までにICMP ECHO REPLYが返ってこなかった場合は,計測を(一時)中断します.最後のvオプションは,付属的な情報を標準出力へ出力します.主にデバッグ用です.