CubeICE の利用動機の一つとして Mac などで作成された zip ファイルを解凍する際に文字化けしない と言うものが挙げられます。この記事では、なぜ文字化けが発生するのかと言う基本的な情報から、Windows における主要な解凍ソフトの対応状況までを簡単に紹介していきます。
必ずしも UTF-8 の zip ファイル解凍時に文字化けする訳ではない
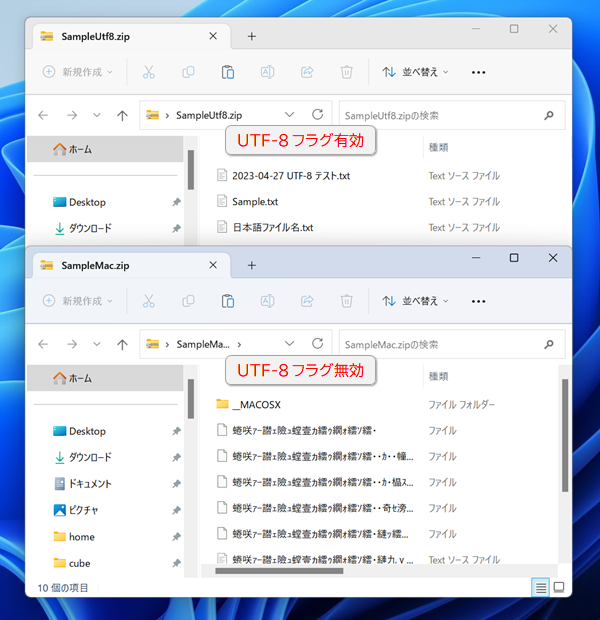
Mac で作成された zip ファイルを Windows で解凍すると文字化けする原因は、Mac (Windows 以外) で採用されている文字コードが UTF-8 なので、日本語用 Windows で採用されている Shift_JIS (CP932) と異なるからと言われます。ただ、Windows 標準の解凍機能を用いた場合でも、必ずしも UTF-8 の zip ファイルで文字化けする訳ではありません。例えば、CubeICE には UTF-8 のファイル名で圧縮ファイルを作成する圧縮用オプションが存在します(CubeICE 設定の圧縮の項目を参照)。このオプションを有効にして作成した zip ファイルを Windows 標準機能を用いて解凍しても、文字化けは発生しません。
これは、現在の zip ファイルの仕様には 所謂 UTF-8 フラグ と言うものが定義されているためです。PKWARE の .ZIP File Format Specification によると、2006 年 9 月 29 日に公開されたバージョン 6.3.0 において、zip ファイルのヘッダー情報に記載されているファイル名やコメントが UTF-8 である事を明示するためのビットフラグが追加されました。
一方、Mac で zip ファイルを作成した場合、ファイル名等は UTF-8 で記載されるものの、残念ながら UTF-8 フラグは設定されないようです。その結果、Windows 標準機能を含め、文字コードに対して UTF-8 フラグの有無以外の付加的なチェックを行っていない解凍ソフトは文字化けを引き起こします(この観点から見ると、zip ファイルを作成する側による予防策としては、UTF-8 フラグを設定する圧縮ソフトを使用する事が挙げられます)。
7-Zip の対策方法
文字化け対策で人気の高い解凍ソフトの一つとして 7-Zip が挙げられます。7-Zip はソースコードが公開されているため、ここでは具体的に 7-Zip の文字化け対策部分のコードを紹介してみたいと思います。尚、分かりやすくするため、一部省略したり、コメントを追加したりしています。
// bool IsUtf8() const { return (Flags & NFileHeader::NFlags::kUtf8) != 0; } bool isUtf8 = IsUtf8(); if (!isUtf8) { /* 中略 */ #ifdef _WIN32 else if (GetHostOS() == NFileHeader::NHostOS::kUnix) { /* Some ZIP archives in Unix use UTF-8 encoding without Utf8 flag in header. We try to get name as UTF-8. Do we need to do it in POSIX version also? */ isUtf8 = true; /* 21.02: we want to ignore UTF-8 errors to support file paths that are mixed of UTF-8 and non-UTF-8 characters. */ // ignore_Utf8_Errors = false; // ignore_Utf8_Errors = true; } #endif } if (isUtf8) { ConvertUTF8ToUnicode(s, res); return; }
7-Zip では、まず仕様に従って UTF-8 フラグが設定されているかどうかをチェックしています。これに加えて、7-Zip では OS フラグが UNIX の場合にも UTF-8 として処理を試みます。ソースコードを見る限りでは、7-Zip で解凍すると文字化けが発生しないのは、現代の Mac で作成された zip ファイルは OS フラグに UNIX が設定されているからだろうと予想されます。
CubeICE の対策方法
CubeICE は、前述した 7-Zip を一部改変した上で、ライブラリ部分 (7z.dll) を利用して実現しています(改変したソースコードは、GitHub - Cube.Native.SevenZip にて公開しています) 。その改変箇所の一つが UTF-8 に関わる部分です。CubeICE では文字コードの判別の際に、zip ファイルにのヘッダー情報に記載されている各種フラグではなく、ファイル名として記載されている文字列自体を利用して文字コードを推測・判別しています。
UTF-8 と言う文字符号化方式は、ある文字列を与えられた時に、それが UTF-8 かそうではないかを判別可能となっており、UTF-8 として処理すべきであったのに見逃すと言う誤判定が発生しづらい仕様となっています。そのため、あくまで推測でしかなかった Shift_JIS と EUC-JP の判別に比べると、変換ミスの頻度を減少させる事ができます。
懸念点としては、zip ファイルに含まれるファイル数が膨大になった場合に、増加する処理時間が無視できなくなる可能性が挙げられます。ただ、開発環境でテストした限りでは、数十万ファイル程度までであれば気になるほどの処理時間の差は確認できなかったため、総合的な利便性も考慮して、CubeICE ではこの方式を採用する事にしています。